
😏 서론
개발을 하면서, 유니크한 값을 사용할 일이 많습니다.
예를 들어 PK가 있을 수도 있고, 쿠폰번호가 있을 수도 있고, 결제번호가 될수도 있습니다.
유니크한 값을 만드는 방식들은 어떤 게 있고, 어떤 상황에 어떤 방식을 사용하는 게 좋을지 정리를 해보겠습니다.
😎 본론
먼저 3가지의 유니크 ID를 생성 종류에 대해서 알아보고 각각 어떨 때 적용하면 좋을지에 대해 개인적인 생각을 적어보겠습니다!
1. RDBMS 의 Auto Increment
디비에서 자동으로 만들어주는 자동증가 값으로 PK 용도로 사용된다.
장점
- 구현이 매우 간단하다.
- 숫자 증가기 때문에 재정렬이 필요 없다.
- 순서가 보장된다.
- 물리삭제가 되지 않는 특성의 테이블의 경우 마지막 row id 값만으로도 대략 테이블 데이터의 수를 파악할 수 있다.
단점
- 1대의 DB에서 생성하기 때문에 스케일 아웃을 통한 확장을 할 수 없다.
- 따라서 처리 성능을 확장하기 어렵다.
- insert 후에야 PK값이 생성되기 때문에 디비에 저장되기 전에는 id를 알 수 없다. (디비에 디펜던시가 생기게 된다.)
2. UUID
GUID (Globally Unique IDentifier)라고도 하는 UUID (Universally Unique IDentifier)는
네트워크 상에서 고유성이 보장되는 ID를 만들기 위한 표준 규약이다.
특징
- 128 Bit 데이터로 표현한다.
- 5개의 그룹으로 8-4-4-4-12 형식으로 총 36자 (32개의 영숫자 및 4개의 하이픈)
구성
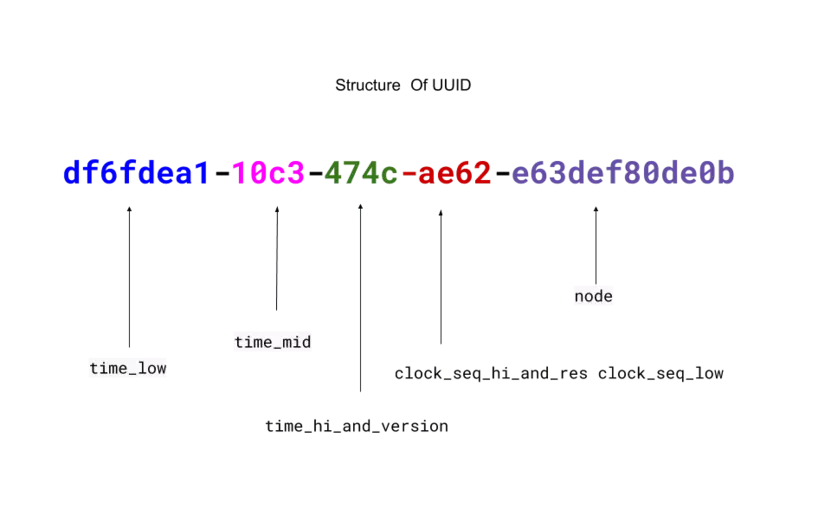
| 이름 | 길이 (Bit) | 내용 |
| time_low | 8 | 시간의 low 32비트를 부여하는 정수 |
| time_mid | 4 | 시간의 middle 16비트를 부여하는 정수 |
| time_hi_and_version | 4 | 최상위 비트에서 4비트 "version", 그리고 시간의 high 12비트 |
| clock_seq_hi_and_res clock_seq_low | 4 | 최상위 비트에서 1-3비트, 그리고 13-15비트 클럭 시퀀스 |
| node | 12 | 48비트 노드 ID |
장점
- 멀티환경에서도 병렬로 동작하기 때문에 유일한 ID를 생성할 수 있다.
- 자바에서 UUID를 제공해주기 때문에 쉽게 사용할 수 있다.
단점
- 128bit로 너무 길고, 데이터베이스에서 많은 공간을 차지하므로 인덱스 구축에 적합하지 않다.
랜덤으로 된 문자와 숫자의 조합으로 사용자가 알아보기 힘들다.
3. SnowFlake
Twitter에서 OSS로 공개하고 있는 ID 생성기 (현재 초기버전은 종료되고 별도 라이브러리로 제공되고 있음)
https://github.com/twitter/snowflake
특징
- Time-base로 한 ID
- 64 Bit의 Long 값으로 데이터로 표현한다.
구성
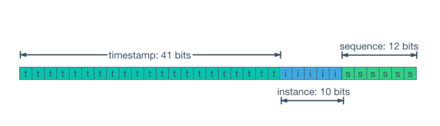
| 이름 | 길이(Bit) | 내용 |
| timestamp | 41 | epoch time으로 millisec 혹은 sec 단위 |
| instance | 10 | Machine ID |
| sequence | 12 | 1밀리초 이내에 동시에 생성된 일련번호 같은 시간, 같은 머신에서 중복되는는 것을 방지 |
장점
- 멀티 환경에서도 병렬로 동작하기 때문에 유일한 ID를 생성할 수 있다.
- 1초 당 생성 가능한 개수가 4,096,000 개로 매우 빠른 속도로 생성이 가능하다.
- timestamp 값을 기초로 하기 때문에 ID 정렬이 가능하다.
- ID 값에서 ID 생성시의 timestamp 값을 복원할 수 있다.
- 정수 열 압축을 이용한 효율적인 정보 압축이 가능하다.
단점
- OS의 시각 차이에 약하다.
- 시간이 잘못 역전될 경우 고장이 발생할 수도 있고, 재가동 후 시간이 초과될 수 있다.
- ID 채번 시에 snowflake 서버에 thrift 경유로 접속하도록 되어 있다.
🤔 어떨 때 뭘 쓸까?
테이블의 PK
PK는 Auto Increment를 사용하는 게 가장 좋다고 생각합니다.
샤딩이 적용된 프로젝트의 경우에는 어쩔 수 없이 다른 방법을 써야겠지만, 아닌 경우에는 장점이 너무 많다고 느껴집니다.
db에서 알아서 최적화를 잘 해주기 때문에 성능도 크게 신경 쓸 필요가 없고,
자동증가로 인해 정렬도 신경 쓸 필요가 없고,
페이징을 할 때에도 ID 값으로 효율적으로 진행할 수 있는 여러 큰 장점들이 있습니다.
다만, 자동증가로 인한 단점으로는 외부에 노출됐을 경우입니다.
만약 유저의 pk 값으로 유저의 정보를 조회하는 서비스가 있다고 가정을 해봅시다.
저의 pk값이 41일 경우 마음먹고 악용한다고 한다면, 42 43 .. 등 다른 값을 날려서 다른 사용자의 정보를 볼 수 있게 될 것입니다.
이처럼 pk값을 외부로 노출하게 되면 사용자에게 악용될 여지를 남겨두는 것이라 생각합니다.
이럴 때 UUID나 snowflake 를 사용한다면 사용자가 다음 값을 추측하기 어려워집니다.
그렇다고, PK값을 Auto Increment 대신 UUID나 snowflake를 사용하는 건 위에 말했던
Auto Increment의 장점을 다 버리는 것이기 때문에 그것보단 별도 컬럼을 추가해서 외부 노출용 ID를 만드는 게 좋다고 생각합니다.
쿠폰
의미 있는 값(예를 들어 중복사용이 가능한 이벤트 쿠폰)을 직접 기입할 수도 있고, 유니크한 값을 만들 수도 있는 쿠폰의 경우
유니크한 값을 만들 때에는 UUID나 snowflake를 적용해보는 것을 고민해볼 수 있을 것 같습니다.
하지만, 본인의 도메인에 적합한 유니크한 값을 만들려고 할 때도 있습니다.
그럴 땐 UUID와 snowflake의 구성을 보고 본인 서비스에 맞는 유니크한 값 생성하는 로직을 만들어보면 될 것 같습니다.
예를 들어..
영화예매번호
CGV의 경우 0041-0802-xxxx-xxx 이러한 번호를 사용 중입니다.
앞의 4자리는 상영관 고유번호, 두번 째 4자리는 예매 날짜
3 - 4 번째는 시퀀스로 판단됩니다.
이처럼 상황에 따라 직접 고유번호를 만들어서 사용하는 것도 생각해보면 좋습니다!
🥹 결론
UUID와 snowflake를 활용하면 String이나 Long타입의 유니크한 값을 쉽게 만들 수 있습니다.
하지만, 본인 도메인과 현 상황에 맞는 유니크한 값을 직접 만들고 싶을 수도 있습니다.
그럴 때에는 다른 GUID는 어떤 식으로 만드는지에 대한 구성을 살펴보고, 영감을 얻는 게 좋습니다.
snowflake에서 영감을 받아 만든 generate id 가 있습니다.
어떤 식으로 만들었는지 참고하면 좋을 것 같습니다. (링크)
참고
https://www.slideshare.net/jacking/twitter-snowflake
https://www.huskyhoochu.com/what-is-uuid/
https://darkstart.tistory.com/147
https://howtodoinjava.com/java/java-uuid/
https://developpaper.com/talking-about-distributed-unique-id-this-article-is-very-real/
https://www.baeldung.com/java-generate-alphanumeric-uuid
baeldung.com/java-uuid
'DataBase' 카테고리의 다른 글
| [SQL] MODIFY 시 기존 옵션 조심! (0) | 2022.12.23 |
|---|---|
| [DB] 락(Lock) - MySQL 8.0 InnoDB (0) | 2022.08.07 |
| [Redis] 레디스 선택하는 이유 (6) | 2022.06.16 |
| [MySQL] Unknown column 'password' in 'field list' (0) | 2022.05.02 |
| [MySQL] Mac M1 에서 MySQL password 재설정 (2) | 2022.04.25 |
😏 서론
개발을 하면서, 유니크한 값을 사용할 일이 많습니다.
예를 들어 PK가 있을 수도 있고, 쿠폰번호가 있을 수도 있고, 결제번호가 될수도 있습니다.
유니크한 값을 만드는 방식들은 어떤 게 있고, 어떤 상황에 어떤 방식을 사용하는 게 좋을지 정리를 해보겠습니다.
😎 본론
먼저 3가지의 유니크 ID를 생성 종류에 대해서 알아보고 각각 어떨 때 적용하면 좋을지에 대해 개인적인 생각을 적어보겠습니다!
1. RDBMS 의 Auto Increment
디비에서 자동으로 만들어주는 자동증가 값으로 PK 용도로 사용된다.
장점
- 구현이 매우 간단하다.
- 숫자 증가기 때문에 재정렬이 필요 없다.
- 순서가 보장된다.
- 물리삭제가 되지 않는 특성의 테이블의 경우 마지막 row id 값만으로도 대략 테이블 데이터의 수를 파악할 수 있다.
단점
- 1대의 DB에서 생성하기 때문에 스케일 아웃을 통한 확장을 할 수 없다.
- 따라서 처리 성능을 확장하기 어렵다.
- insert 후에야 PK값이 생성되기 때문에 디비에 저장되기 전에는 id를 알 수 없다. (디비에 디펜던시가 생기게 된다.)
2. UUID
GUID (Globally Unique IDentifier)라고도 하는 UUID (Universally Unique IDentifier)는
네트워크 상에서 고유성이 보장되는 ID를 만들기 위한 표준 규약이다.
특징
- 128 Bit 데이터로 표현한다.
- 5개의 그룹으로 8-4-4-4-12 형식으로 총 36자 (32개의 영숫자 및 4개의 하이픈)
구성
| 이름 | 길이 (Bit) | 내용 |
| time_low | 8 | 시간의 low 32비트를 부여하는 정수 |
| time_mid | 4 | 시간의 middle 16비트를 부여하는 정수 |
| time_hi_and_version | 4 | 최상위 비트에서 4비트 "version", 그리고 시간의 high 12비트 |
| clock_seq_hi_and_res clock_seq_low | 4 | 최상위 비트에서 1-3비트, 그리고 13-15비트 클럭 시퀀스 |
| node | 12 | 48비트 노드 ID |
장점
- 멀티환경에서도 병렬로 동작하기 때문에 유일한 ID를 생성할 수 있다.
- 자바에서 UUID를 제공해주기 때문에 쉽게 사용할 수 있다.
단점
- 128bit로 너무 길고, 데이터베이스에서 많은 공간을 차지하므로 인덱스 구축에 적합하지 않다.
랜덤으로 된 문자와 숫자의 조합으로 사용자가 알아보기 힘들다.
3. SnowFlake
Twitter에서 OSS로 공개하고 있는 ID 생성기 (현재 초기버전은 종료되고 별도 라이브러리로 제공되고 있음)
https://github.com/twitter/snowflake
특징
- Time-base로 한 ID
- 64 Bit의 Long 값으로 데이터로 표현한다.
구성
| 이름 | 길이(Bit) | 내용 |
| timestamp | 41 | epoch time으로 millisec 혹은 sec 단위 |
| instance | 10 | Machine ID |
| sequence | 12 | 1밀리초 이내에 동시에 생성된 일련번호 같은 시간, 같은 머신에서 중복되는는 것을 방지 |
장점
- 멀티 환경에서도 병렬로 동작하기 때문에 유일한 ID를 생성할 수 있다.
- 1초 당 생성 가능한 개수가 4,096,000 개로 매우 빠른 속도로 생성이 가능하다.
- timestamp 값을 기초로 하기 때문에 ID 정렬이 가능하다.
- ID 값에서 ID 생성시의 timestamp 값을 복원할 수 있다.
- 정수 열 압축을 이용한 효율적인 정보 압축이 가능하다.
단점
- OS의 시각 차이에 약하다.
- 시간이 잘못 역전될 경우 고장이 발생할 수도 있고, 재가동 후 시간이 초과될 수 있다.
- ID 채번 시에 snowflake 서버에 thrift 경유로 접속하도록 되어 있다.
🤔 어떨 때 뭘 쓸까?
테이블의 PK
PK는 Auto Increment를 사용하는 게 가장 좋다고 생각합니다.
샤딩이 적용된 프로젝트의 경우에는 어쩔 수 없이 다른 방법을 써야겠지만, 아닌 경우에는 장점이 너무 많다고 느껴집니다.
db에서 알아서 최적화를 잘 해주기 때문에 성능도 크게 신경 쓸 필요가 없고,
자동증가로 인해 정렬도 신경 쓸 필요가 없고,
페이징을 할 때에도 ID 값으로 효율적으로 진행할 수 있는 여러 큰 장점들이 있습니다.
다만, 자동증가로 인한 단점으로는 외부에 노출됐을 경우입니다.
만약 유저의 pk 값으로 유저의 정보를 조회하는 서비스가 있다고 가정을 해봅시다.
저의 pk값이 41일 경우 마음먹고 악용한다고 한다면, 42 43 .. 등 다른 값을 날려서 다른 사용자의 정보를 볼 수 있게 될 것입니다.
이처럼 pk값을 외부로 노출하게 되면 사용자에게 악용될 여지를 남겨두는 것이라 생각합니다.
이럴 때 UUID나 snowflake 를 사용한다면 사용자가 다음 값을 추측하기 어려워집니다.
그렇다고, PK값을 Auto Increment 대신 UUID나 snowflake를 사용하는 건 위에 말했던
Auto Increment의 장점을 다 버리는 것이기 때문에 그것보단 별도 컬럼을 추가해서 외부 노출용 ID를 만드는 게 좋다고 생각합니다.
쿠폰
의미 있는 값(예를 들어 중복사용이 가능한 이벤트 쿠폰)을 직접 기입할 수도 있고, 유니크한 값을 만들 수도 있는 쿠폰의 경우
유니크한 값을 만들 때에는 UUID나 snowflake를 적용해보는 것을 고민해볼 수 있을 것 같습니다.
하지만, 본인의 도메인에 적합한 유니크한 값을 만들려고 할 때도 있습니다.
그럴 땐 UUID와 snowflake의 구성을 보고 본인 서비스에 맞는 유니크한 값 생성하는 로직을 만들어보면 될 것 같습니다.
예를 들어..
영화예매번호
CGV의 경우 0041-0802-xxxx-xxx 이러한 번호를 사용 중입니다.
앞의 4자리는 상영관 고유번호, 두번 째 4자리는 예매 날짜
3 - 4 번째는 시퀀스로 판단됩니다.
이처럼 상황에 따라 직접 고유번호를 만들어서 사용하는 것도 생각해보면 좋습니다!
🥹 결론
UUID와 snowflake를 활용하면 String이나 Long타입의 유니크한 값을 쉽게 만들 수 있습니다.
하지만, 본인 도메인과 현 상황에 맞는 유니크한 값을 직접 만들고 싶을 수도 있습니다.
그럴 때에는 다른 GUID는 어떤 식으로 만드는지에 대한 구성을 살펴보고, 영감을 얻는 게 좋습니다.
snowflake에서 영감을 받아 만든 generate id 가 있습니다.
어떤 식으로 만들었는지 참고하면 좋을 것 같습니다. (링크)
참고
https://www.slideshare.net/jacking/twitter-snowflake
https://www.huskyhoochu.com/what-is-uuid/
https://darkstart.tistory.com/147
https://howtodoinjava.com/java/java-uuid/
https://developpaper.com/talking-about-distributed-unique-id-this-article-is-very-real/
https://www.baeldung.com/java-generate-alphanumeric-uuid
baeldung.com/java-uuid
'DataBase' 카테고리의 다른 글
| [SQL] MODIFY 시 기존 옵션 조심! (0) | 2022.12.23 |
|---|---|
| [DB] 락(Lock) - MySQL 8.0 InnoDB (0) | 2022.08.07 |
| [Redis] 레디스 선택하는 이유 (6) | 2022.06.16 |
| [MySQL] Unknown column 'password' in 'field list' (0) | 2022.05.02 |
| [MySQL] Mac M1 에서 MySQL password 재설정 (2) | 2022.04.25 |